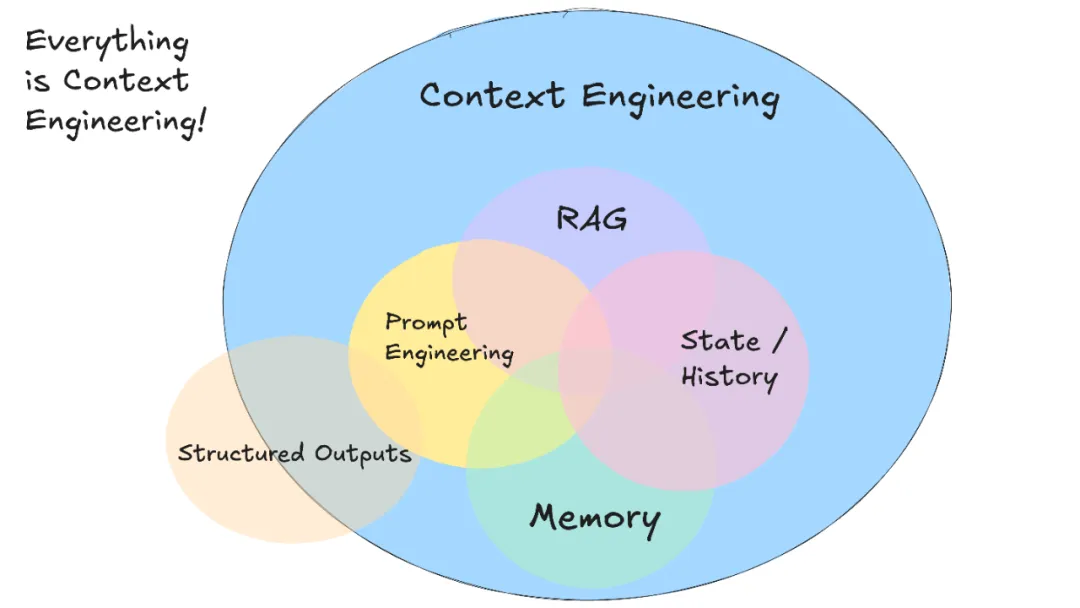
是什么 Context Engineering
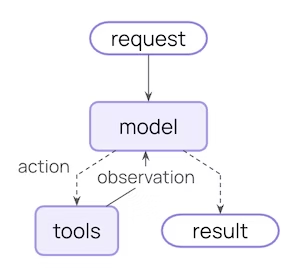
先来看一小段最小化 Agent Loop 的伪代码实现:
def agent_loop():
context = []
while True:
# 1. 构造 instruction
prompt = SYSTEM_PROMPT
message = [prompt] + context
# 2. 调用 LLM 接口
response = llm(msg=message)
# 3. 解析结果并更新上下文
result = parse_reponse(response)
context.append(result)
if is_done(result):
return result
从这段简化代码可以发现:在循环结束前,所有的对话信息都是通过 context 数组进行保存。这个保存的”对话信息”,也就是模型在执行所需要的信息集合,就是上下文(Context)。
之所以需要这个数组,是因为大语言模型(LLM)是无状态(Stateless,状态是指对话历史、系统设定等上下文信息,无状态意味着模型不会保留相关的对话信息)的,它的每一次生成都是基于当前输入序列进行条件概率计算。但为了让用户感知到“状态”存在,就需要编程人员在应用层构建这样一个数组或者类似数据结构,来保存相关状态,并将其传递给 LLM 用于生成(预测)文本。
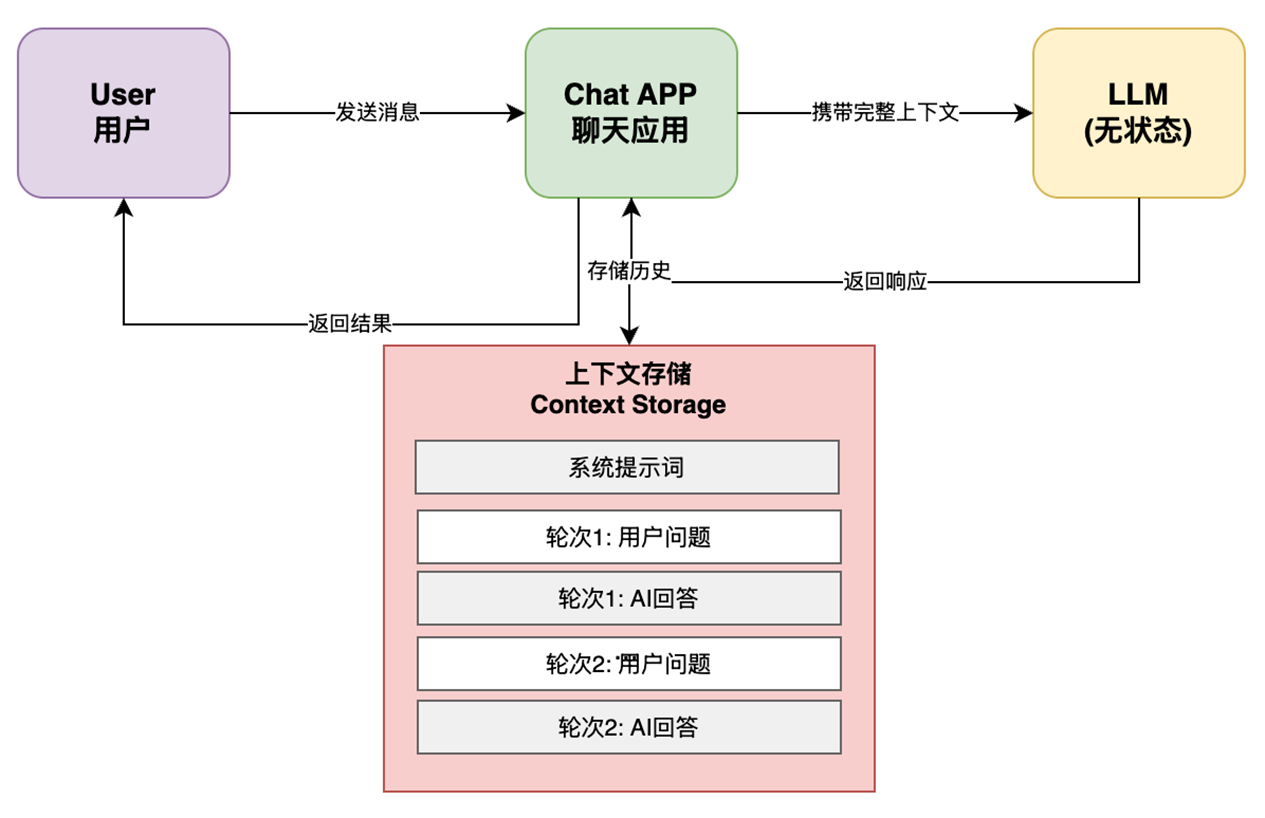
可是这样就带来一个问题:
随着对话轮次的增加, context 数组中存储的内容会越来越多,尤其是在加入任务分解,工具调用等复杂功能后,会使得上下文的长度快速膨胀。而又由于每个模型都存在相应的 Context Window 限制,当内容的 Token 超过规定限度后,模型就会通过截断的方式遗忘掉之前的内容。
因此,Context Engineering 第一个最直接的作用便是:控制上下文长度。
或许你会猜想:那是不是上下文足够长,就行了?其实不然,随着上下文内容的增加,各种冗余信息会造成模型的注意力分散,从而使的模型从该上下文中准确回忆信息的能力降低1。
因此 Context Engineering 的第二个作用就是:让你的 Agent 在长对话中也能保持专注。
在对上述场景有一定了解之后,再来看看这篇文章对 Context Engineering 的定义:
通过设计、优化指令以及相关上下文的加载,从而使得AI模型能够更高效的工作。
说白了,同 Prompt、Skills、Harness 一样, Context Engineering 也为了让 LLM 更高效且朝向保持理想方向运行,从而产生 准确、可靠、符合预期的输出,只不过具体关注的点不一样。Context Engineering 更注重于 Context 的动态加载部分。
为什么需要Context Engineering
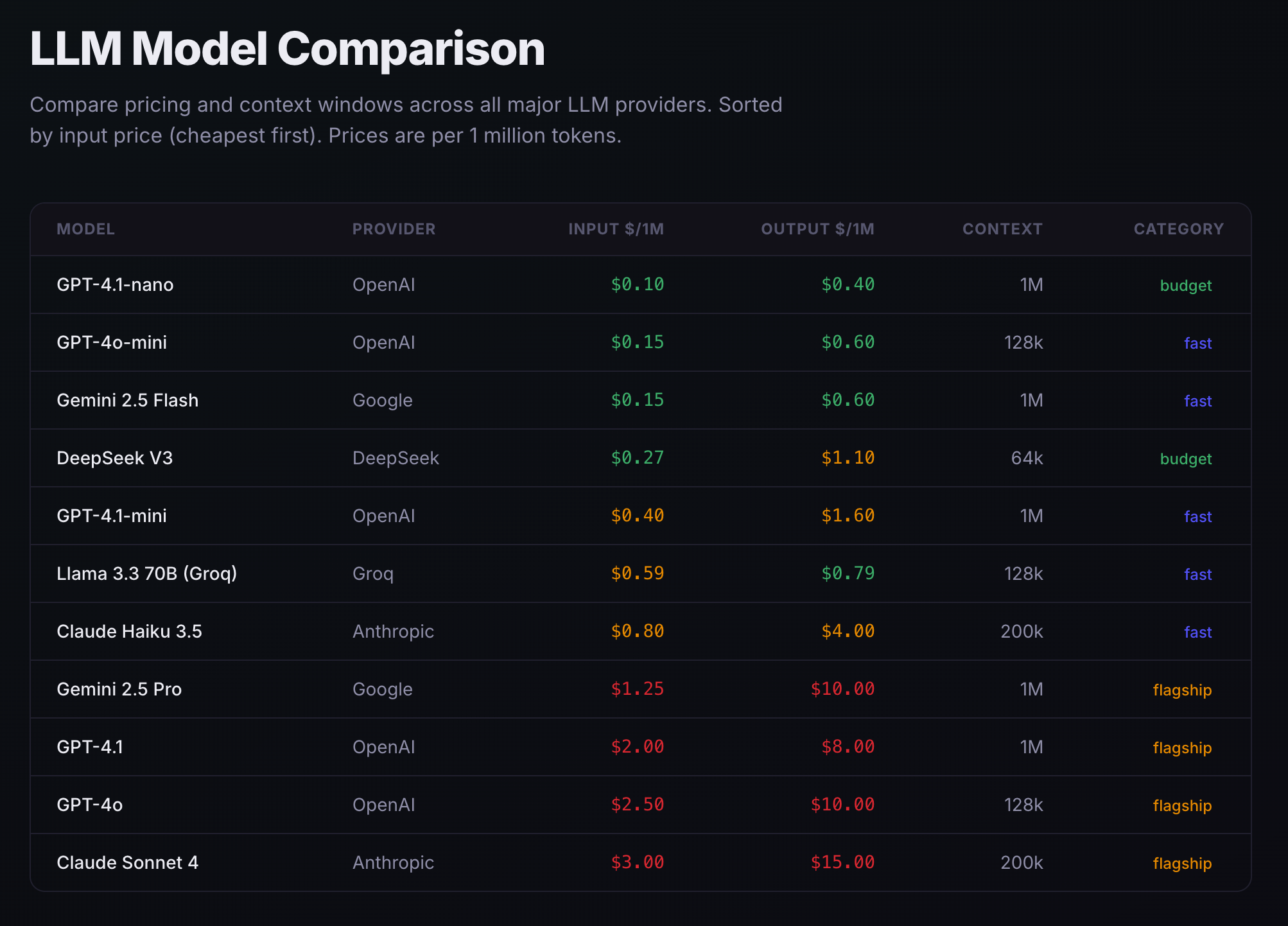
除了上述提到的容量管理以及提高推理准确性外,还有另外一个不可忽视的因素:成本控制。
下图展示了不同提供商输入/输入 1M 所需的费用。对比 Deepseek V3.2($0.252/M input tokens) 和 Claude Opus 4.6($3/M input tokens),仅每百万的token花费价格就差约12倍。
由上章节的 Agent Loop 伪代码可知,每一轮请求都会携带完整的历史上下文,这使得在复杂任务(如代码分析、工具调用链)中,一个 Agent 任务很容易达到:
-
单轮上下文:10k ~ 50k tokens;
-
总轮次:10 ~ 20 轮。
从而导致最终的 token 消耗可能达到数百万级别。此时,模型之间的价格差异会被进一步放大。因此,成本累积会变得不可忽视。
实践案例
前文中,我们从背景层面讨论了 Context Engineering 的作用以及必要性。但在真实系统中,这些问题是如何被解决的?本节将从实践案例出发,分析主流 Agent 的上下文管理策略。
需要说明的是,Context Engineering 的设计空间非常广泛(信息选择、表示、压缩、生命周期等),并且随着新范式的出现(如 skills、harness 等),其设计方式也在不断演进。为了聚焦核心问题,本文选择一个最基础但最关键的切入点:上下文长度管理。
因为在大多数 Agent 系统中,几乎所有策略(summary、memory、tool 管理)的第一驱动力,都是对 context window 的约束响应。
接下来将通过 Claude Code 与 DeepAgents 两个案例的实现,来观察这些策略在真实系统中的具体落地方式。
Claude Code - By Anthropic
Claude Code 是一款人工智能驱动的编码助手,它可以读取代码库、编辑文件、执行命令,并通过与开发工具集成等,帮助用户构建功能、修复漏洞并自动化开发任务。
2026年3月31日,一位研究员通过 Anthropic 发布 npm 包中意外泄漏的 cli.js.map 文件,还原了部分的 Claude Code 源代码。借此机会,来学习一下该 Agent 是如何进行上下文长度管理的。
分层压缩管线
Claude Code 采用了一种分层压缩策略来进行长度控制,通过在不同成本与触发条件下组合多种压缩机制,实现对上下文长度的精细化管理。
该设计类似于 CPU cache(L1/L2/L3)或 JVM 分代 GC,其核心思想在于:将不同生命周期与信息密度的数据分层处理,以在性能与成本之间取得平衡2。
压缩策略主要分为三层:
- Microcompact(免费,每次迭代运行): 清理旧工具结果,将过时内容替换为
[Old tool result content cleared],几乎无计算成本 - Autocompact(API 调用,阈值触发): 调用 LLM 生成摘要替换整段对话历史,需要消耗 API 调用额度
- Reactive(应急,413 触发): 在 API 返回
prompt_too_long错误时触发,作为最后的安全网

接下来看看具体的实现逻辑:
Snip Compact:精细化压缩
该策略通过对上下文的中间消息进行**“局部裁剪”**,从而在一定程度上缩短了上下文的长度。
具体如下:
首先,Snip Compact 策略需要通过启用HISTORY_SNIP 特性标志进行开启:
const snipModule = feature('HISTORY_SNIP')
? require('./services/compact/snipCompact.js')
: null
具体的关键函数源码的如下:
// src/utils/sessionStorage.ts
// 代码经过简化
function applySnip(messages: Map<UUID, Message>) {
// 1. 找出所有需要删除的消息 ID
const toDelete = collectSnippedIds(messages)
if (toDelete.size === 0) return
// 2. 删除这些消息(同时记录它们的 parent 关系)
const parentMap = removeMessages(messages, toDelete)
// 3. 修复剩余消息的 parent 链
relinkParents(messages, toDelete, parentMap)
}
Micro Compact:微型压缩
该策略同样是对上下文进行**“局部裁剪”,从而缩短上下文的长度。与Snip Compact不同之处在于,MicroCompact 专注于优先清理“低价值但高体积”的可重建**信息(如工具输出);而Snip Compact 则专注于删除整个消息的中间范围,通过移除完整的对话片段来管理长时间会话的内存使用,保持对话结构的完整性。
其核心代码如下:
microCompact.ts 文件中定义了需要替换的工具集合以及占位符:
// src/services/compact/microCompact.ts#L36
export const TIME_BASED_MC_CLEARED_MESSAGE = '[Old tool result content cleared]'
// Only compact these tools
const COMPACTABLE_TOOLS = new Set<string>([
FILE_READ_TOOL_NAME, // FileRead
...SHELL_TOOL_NAMES, // Bash, PowerShell
GREP_TOOL_NAME, // Grep
GLOB_TOOL_NAME, // Glob
WEB_SEARCH_TOOL_NAME, // WebSearch
WEB_FETCH_TOOL_NAME, // WebFetch
FILE_EDIT_TOOL_NAME, // FileEdit
FILE_WRITE_TOOL_NAME, // FileWrite
])
并通过“距离上次助手消息超过配置阈值”作为条件进行执行 microCompact.ts :
//src/services/compact/microCompact.ts#L401
export function evaluateTimeBasedTrigger(
messages: Message[],
querySource: QuerySource | undefined,
): { gapMinutes: number; config: TimeBasedMCConfig } | null {
const config = getTimeBasedMCConfig()
// Require an explicit main-thread querySource. isMainThreadSource treats
// undefined as main-thread (for cached-MC backward-compat), but several
// callers (/context, /compact, analyzeContext) invoke microcompactMessages
// without a source for analysis-only purposes — they should not trigger.
if (!config.enabled || !querySource || !isMainThreadSource(querySource)) {
return null
}
const lastAssistant = messages.findLast(m => m.type === 'assistant')
if (!lastAssistant) {
return null
}
const gapMinutes =
(Date.now() - new Date(lastAssistant.timestamp).getTime()) / 60_000
if (!Number.isFinite(gapMinutes) || gapMinutes < config.gapThresholdMinutes) {
return null
}
return { gapMinutes, config }
}
Context Collapse:极端压缩
该策略需要启用CONTEXT_COLLAPSE 特性标志,根据注释可知,其核心目的是:
通过 90% 提交开始、95% 阻塞生成的主动策略来管理上下文窗口的余量问题,同时抑制传统的自动压缩机制,因为传统压缩会在约 93% 的有效上下文时触发,正好位于 Collapse 的提交起点(90%)和阻塞点(95%)之间,会导致竞争并通常胜出,从而破坏 Collapse 即将保存的细粒度上下文
Auto Compact:自动压缩
与前两个局部裁剪的策略不同,Auto Compcat 通过特定算法找到压缩边界,并对边界内的所有对话历史进行语义压缩,提高信息密度,从而减少上下文。
其策略核心流程如下:
首先通过 calculateTokenWarningState 函数 来判断是否应该执行压缩,当token消耗量占规定token的85%时,给予建议压缩,当占用率超过95%时,执行强制压缩:
// src/services/compact/autoCompact.ts
export function calculateTokenWarningState(
messages: Message[],
maxTokens: number
): TokenWarningState {
const currentTokens = estimateTokenCount(messages)
const ratio = currentTokens / maxTokens
if (ratio > 0.95) {
return 'critical' // 必须立即压缩
} else if (ratio > 0.85) {
return 'warning' // 建议压缩
} else {
return 'normal'
}
}
export function isAutoCompactEnabled(): boolean {
// 检查用户配置和环境变量
return !isEnvTruthy(process.env.CLAUDE_CODE_DISABLE_AUTO_COMPACT)
}
// src/services/compact/compact.ts(简化)
async function compactConversation(
messages: Message[],
systemPrompt: SystemPrompt
): Promise<Message[]> {
// 1. 找到压缩边界(保留最近的 N 条消息不压缩)
const { toCompress, toKeep } = splitAtCompactBoundary(messages)
// 2. 用 Claude 生成摘要
const summary = await generateSummary(toCompress, systemPrompt)
// 3. 构建压缩后的消息列表
return [
// 摘要作为第一条用户消息
createUserMessage({
content: `[对话历史摘要]\n${summary}`
}),
// 保留最近的消息(完整)
...toKeep
]
}
Reactive Compact
Reactive Compact 策略属于一个”防御性”机制:当 API 返回413 Prompt Too Long 错误,通过自动触发压缩并重试,以确保系统在极端情况下仍然可用:
// /src/query.ts
// 当 API 返回 prompt_too_long 错误时,自动触发压缩
const reactiveCompact = feature('REACTIVE_COMPACT')
? require('./services/compact/reactiveCompact.js')
: null
// 在 query.ts 中
if (error.type === 'prompt_too_long') {
if (reactiveCompact) {
// 压缩后重试
messages = await reactiveCompact.compact(messages)
continue // 重新发起请求
}
}
Summary as Compression
Claude Code 中最关键的 Auto Compact 策略是通过 summary 生成摘要并将历史对话代替的形式实现的。这样是否存在问题呢?
Summary 是一种有损压缩。使用 summary 并将原内容替换后,必将产生部分信息的永久的丢失。如何在“有损”中保持“高保真”, 并继续让大语言模型继续按照我们希望的方向继续工作呢?这就关联到 summary 的质量问题。summary 的质量直接决定后续推理能力的上限。
这里笔者将 summary 的质量细分为两个方向:完整性与准确性。
完整性
完整性可以理解为,summary 后的内容能够以较高信息密度的情况下体现出原始内容中的重要信息,如:
-
需要执行的任务
-
已经执行了哪些步骤、解决了哪些问题
-
任务执行过程中的关键决策以及相关结果
-
还有哪些任务需要或者等待处理
准确性
准确性可以理解为, summary 后的信息,是否忠实表达原始语义,如:
- 能否能正确反应原记忆内容
- 是否歪曲用户意图
- 是否添加额外信息或扭曲已有信息3
Claude Code 通过一套严格的结构化指令 Instruction, 从九个方面约束了摘要的“完整性”与“准确性”:
- Primary Request and Intent
- Key Technical Concepts
- Files and Code Sections
- Errors and fixes
- Problem Solving
- All user messages:
- Current Work
- Optional Next Step
DeepAgents - By LangChain
DeepAgents 是 LangChain 开源的一种 harness agent,用于处理复杂的长时间任务,支持任务规划、子代理生成以及文件系统交互等能力。
LangChain 官方在其技术博客中专门提及了 DeepAgents 的 context management 设计。其核心思想可以概括为:优先外置(offloading),延迟压缩(summarization)。也就是说:
-
能不压缩,就不压缩
-
能移出上下文,就不留在上下文
-
只有在“无处可移”时,才进行有损压缩
围绕这一原则,DeepAgents 构建了三层 context 管理机制:
- Offloading large tool results(卸载大型工具输出): 每当大型工具响应发生时,都会将其卸载到文件系统中。
- Offloading large tool inputs(卸载大型工具输入): 当上下文大小超过阈值时,会将工具调用中的旧写入或编辑参数卸载到文件系统。
- Summarization: 当上下文大小超过阈值,且没有更多符合条件的上下文可供卸载时,会执行摘要步骤来压缩消息历史记录。
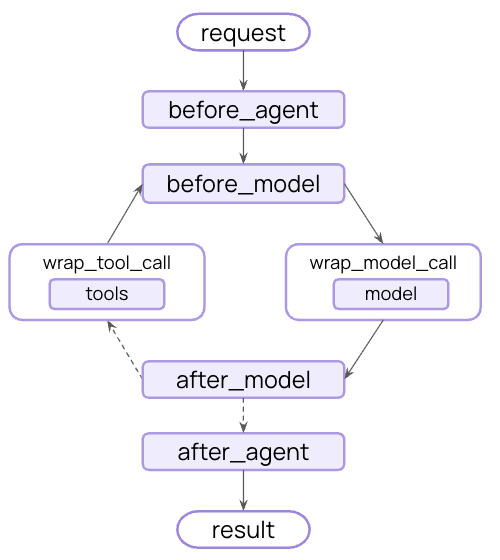
DeepAgents 的这些策略并不是散落在 Agent 逻辑中,而是通过 LangChain 的 Middleware 机制统一实现。
Middleware 可以理解为在模型调用前后插入的“拦截层”(类似hook机制),允许开发者在不修改核心 Agent Loop 的情况下,对上下文进行预处理与后处理(如裁剪、外置、summary 等)。
因此,DeepAgents 的 context management,本质上是通过 Middleware 在“模型调用边界”进行统一调度。
Offloading large tool results:卸载大型工具输出
该策略的关键在于将“高体积但低频访问”的信息从上下文中剥离出来,转化为一种“按需访问”的外部存储。
具体而言,当工具返回内容过大时,DeepAgents 会执行以下逻辑:
- 将完整的工具返回结果保存在“文件系统”中
- 使用文件路径以及部分文件预览作为工具的结果,填充在上下文中
其处理的核心代码在于_process_large_message 函数:
## libs/DeepAgents/DeepAgents/middleware/filesystem.py
## 以下为简化代码
def _process_large_message(message):
# 1. 提取文本内容
content = extract_text(message)
# 2. 判断是否超过阈值
if not exceeds_limit(content):
return message, False
# 3. 写入文件系统
file_path = write_to_filesystem(content)
# 4. 构造替换消息(路径 + 摘要)
preview = create_preview(content)
new_message = build_reference_message(
original=message,
file_path=file_path,
preview=preview
)
return new_message, True
Offloading large tool inputs:卸载大型工具输入
与工具输出类似,工具调用的输入参数(尤其是文件写入、编辑操作)往往包含大量冗余内容,例如完整文件内容。
但与输出不同的是:
- 输出是“结果数据”
- 输入是“执行记录”
一旦这些操作已经成功执行,并且结果已被持久化到文件系统中,这些输入参数本身就失去了继续存在于上下文中的必要性。
因此,DeepAgents 在上下文接近阈值(可用窗口的85%)时,会优先裁剪这些“已生效”的历史操作参数,并用文件引用进行替代。
相关核心代码主要位于truncat_args 函数:
## libs/DeepAgents/DeepAgents/middleware/summarization.py#L674
## 以下为简化代码
def _truncate_args(messages: list[AnyMessage]):
# 1. 判断是否需要触发
if not context_exceeds_threshold(messages):
return messages, False
cutoff = find_truncation_boundary(messages)
new_messages = []
modified = False
for i, msg in enumerate(messages):
# 2. 只处理较早的消息
if i < cutoff and is_tool_call_message(msg):
new_calls = []
for call in msg.tool_calls:
# 3. 仅裁剪文件操作类调用
if call.name in ["write_file", "edit_file"]:
new_calls.append(truncate_call(call))
modified = True
else:
new_calls.append(call)
msg = replace_tool_calls(msg, new_calls)
new_messages.append(msg)
return new_messages, modified
Summarization
和 Claude Code 类似, DeepAgents 的核心压缩原理也是通过调用 LLM API 来实现。当满足以下条件时, DeepAgents 会触发sumamry:
- 无法继续 offload(没有可转移内容)
- 且 context 已接近上限
与Claude Code 不同之处在于,DeepAgents 在有损 summary 之前,对原文内容进行了备份,以保留其可回溯能力,确保其能在需要时通过文件系统搜索恢复具体细节。
其核心逻辑通过wrap_model_call进行实现:
## libs/DeepAgents/DeepAgents/middleware/summarization.py#L885
## 以下为简化代码
def wrap_model_call(request, handler):
# 0. 获取当前有效上下文(考虑历史 summary)
messages = get_effective_messages(request)
# 1. 预处理:裁剪过大的 tool 参数
messages = truncate_tool_args(messages)
# 2. 判断是否需要 summary(基于 token 使用)
if not should_summarize(messages):
# 2.1 正常调用模型
# 2.2 如果溢出,fallback 到 summary
# 3. 计算压缩边界(只压缩旧消息)
cutoff = determine_cutoff(messages)
if cutoff <= 0:
return handler(request.with_messages(messages))
to_summarize, to_keep = split_messages(messages, cutoff)
# 4. 关键步骤:先持久化原始内容以保留在需要时恢复特定细节的能力
file_path = offload_to_storage(to_summarize)
# 5. 生成 summary(LLM 调用)
summary = generate_summary(to_summarize)
# 6. 构造新的上下文(summary + 最近消息)
new_messages = [
build_summary_message(summary, file_path),
*to_keep
]
# 7. 使用压缩后的上下文重新调用模型
return handler(request.with_messages(new_messages))
为了确保 summary 的质量,DeepAgents 在提示词中通过一下4个方面来尝试约束生成摘要的完整性以及准确性:
SESSION INTENT: 当前目标
SUMMARY: 历史决策
ARTIFACTS: 外部状态
NEXT STEPS: 未来计划
小结:
可以看到,Claude Code 与 DeepAgents 在 context 管理上体现了两种不同的设计哲学:
-
Claude Code:分层压缩
Claude Code 将上下文视为一个“需要被持续维护的工作内存”,并围绕这一点构建了一套分层压缩体系:
-
Micro / Snip:低成本、局部清理(删除或替换可重建信息)
-
Auto Compact:语义压缩(通过 summary 提高信息密度)
-
Reactive:极端情况下的兜底机制
-
-
DeepAgents:优先外置,延迟压缩
DeepAgents 则采取了一种完全不同的路径:尽可能减少 context 中的信息量,将其转化为“可引用的外部状态”:
- 工具输出 → 外置到文件系统
- 工具输入 → 用引用替换历史参数
- summary → 在无法继续外置时才触发(且保留原始备份)
两者的核心差异在于:
是否将“上下文”视为数据本身,还是数据的入口。
总结
写不动了,不知道总结啥了,感谢阅读吧🙏。
参考
- context-engineering-guide
- context-what
- compact
- 上下文管理
- context-management-for-DeepAgents
- 从Prompt Engineering到Context Engineering
- Context Engineering for Agents
- context-engineering
- agentic-ai-infrastructure-practice-series-nine-context-engineering